| |||||||||
|
The Emissia.Offline Letters Электронное научное издание (педагогические и психологические науки) Издается с 7 ноября 1995 г. | |||||||||
|
|||||||||
|
_________ Шифр научной специальности 5.8.7 Готская Ирина Борисовна Игнатьев Денис Сергеевич Щербинин Артем Владимирович
Аннотация Ключевые слова: искусственный интеллект, большие языковые модели, БЯМ, генеративные предобученные трансформеры, GPT. ---------------- Irina B. Gotskaya Denis S. Ignatyev Artem V. Shcherbinin
Abstract Key words: artificial intelligence, large language models, LLM, generative pretrained transformers, GPT. ---------------- Ключевым вызовом современности после появления компьютеров и информатизации по праву рассматриваются развивающиеся технологии искусственного интеллекта (далее – ИИ), с которыми связываются не только технологические прорывы в развитии человечества, но и возможные потенциальные риски. Применительно к системе образования, несмотря на отличающиеся позиции ученых и педагогов-практиков [1], большинство сходятся во мнении о необходимости поиска путей и методов применения технологий ИИ в профессиональной педагогической деятельности. К настоящему времени накоплен первый опыт применения технологии ИИ в общем [2] и высшем [3-5] образовании. Особый интерес в настоящее время представляют системы, построенные на больших языковых моделях (далее - БЯМ), в частности, генеративные предобученные трансформеры (GPT - Generative pre-trained transformer), которые как AI‑ассистенты и AI‑тьюторы [6] находят применение не только в образовании, но и в повседневной жизни (например, виртуальный голосовой помощник «Алиса» от компании Яндекс). Учитывая активное развитие как отечественных, так и зарубежных решений, перед пользователями встаёт задача обоснованного выбора ИИ-модели для практического применения, в том числе в сфере образования. В условиях высокой вариативности архитектур, масштабов обучающих выборок и методологических подходов к дообучению, актуализируется необходимость комплексной экспертной оценки БЯМ. В прикладной практике наиболее значимыми параметрами оценки выступают: способность модели к многоязычной генерации и пониманию текстов; устойчивость к феномену галлюцинирования, заключающемуся в генерации недостоверной или вымышленной информации; последовательность и логичность ответов при соблюдении тематической и семантической целостности; ясность и структурированность формулировок; соответствие генерируемых данных исходной задаче (корректность ответа). Кроме того, принципиальное значение имеют адаптивность модели к контексту ввода и устойчивость к неоднозначным или конфликтующим формулировкам, что позволяет обеспечивать корректную интерпретацию входных данных и повышение надёжности результатов. Для оценки эффективности БЯМ в решении образовательных задач был разработан и проведен эксперимент, целью которого являлось сравнение шести моделей: Grok 3 (xAI), DeepSeek V3 (DeepSeek), ChatGPT-4o (OpenAI), Le Chat (Mistral AI), GigaChat 2 Max (Сбербанк), YandexGPT 5 Pro (Яндекс). В рамках эксперимента были охвачены школьные и вузовские дисциплины, в том числе: алгебра (10–11 классы), геометрия (10–11 классы), информатика (11 класс), физика (11 класс), химия (9 класс), а также разделы высшей математики — интегралы и дифференциальные уравнения (2 курс вуза). По каждой из указанных дисциплин была разработана совокупность из 15 заданий, что в сумме составило 90 задач. Отбор заданий осуществлялся на основе анализа действующих образовательных программ и включал как теоретические, так и практические задачи. Каждая задача решалась в отдельном чате, чтобы исключить влияние контекста предыдущих запросов на результаты. Для задач, содержащих математические формулы, использовался формат LaTeX, обеспечивающий точную передачу условий. Запросы к моделям формировались на русском языке следующим образом: для стандартных задач применялся промпт «Реши задачу по предмету “<Предмет>”. Текст задачи: <Задача>», а для задач с формулами — «Реши задачу по предмету “<Предмет>”. Текст задачи в виде LaTeX-формулы: <Задача>». В случае неверного ответа модели предоставлялась вторая попытка с переформулированным запросом: «Тебе не удалось решить эту задачу. Ответ не соответствует ожидаемому. Забудь свой предыдущий ответ и попробуй решить её ещё раз. Для лучшего результата продублирую задачу: <Задача>». Оценка ответов проводилась по четырем критериям: правильность ответа с первой попытки; полнота ответа; правильность ответа со второй попытки; галлюцинирование — степень отклонения модели от исходной задачи, логики её постановки и связности формируемого ответа. Уточним, под галлюцинированием понимались значительные нарушения когерентности текста или очевидная утрата контекста (необоснованная замена языка в середине ответа; неуместные или бессвязные фрагменты, не относящиеся к содержанию задачи; попытки решения, демонстрирующие утрату контекста задачи). В случае отсутствия подобных отклонений, даже при наличии фактических ошибок, модели присваивалось 0 баллов. При наличии описанных признаков — оценка составляла - 1 балл. Такой подход позволил дифференцировать стандартные ошибки от случаев системной деградации генерации, нарушающей логико-семантические рамки задачи. Максимальная совокупная оценка за выполнение одной задачи составляла 2 балла. Результаты эксперимента свидетельствуют о значительном потенциале БЯМ для применения в обучении. Общая численность заданий в выборке составила 540. Результаты их выполнения распределились следующим образом: количество верных ответов с первой попытки (оценка 2 балла) — 399, частично верных ответов (1 балл) — 87. Общее число вторых попыток составило 143, из которых успешными (верный ответ со второй попытки) оказались 14, а неудачными (ответ остаётся неверным) — 129. Ответы, получившие 0 баллов (полностью неверные), составили 54 случая. Кроме того, было выявлено 3 случая галлюцинирования. Таким образом, доля корректных ответов с первой попытки составляет 73,9% от общего числа заданий. Доля успешных повторных попыток оказалась незначительной — 9,8% от всех вторых попыток, указывает на ограниченную способность моделей переосмысливать задачу и корректировать свои ошибки при переформулировке запроса. Галлюцинации зафиксированы лишь в 3 случаях (менее 1%), что говорит о достаточно высоком уровне надёжности всех моделей. Кроме того, все модели продемонстрировали тенденцию предоставлять полные ответы, даже в случае их некорректности. Этот аспект подчеркивает необходимость контроля для корректной интерпретации и использования таких ответов. Результаты представлены на диаграмме (Рисунок 1).
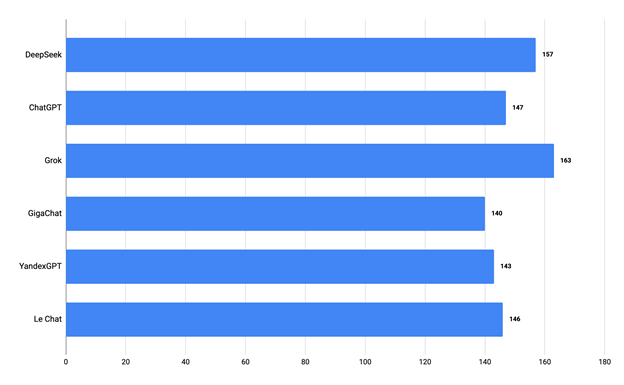
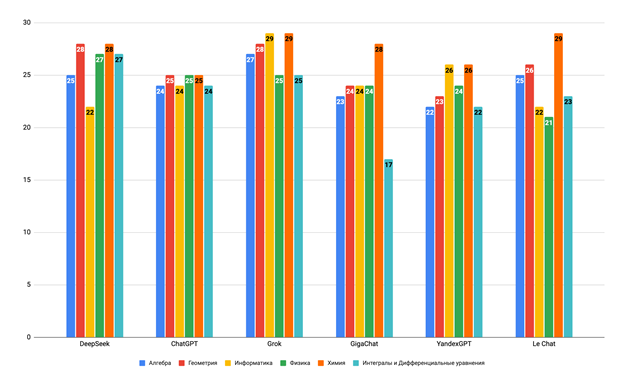
Рис. 1. Диаграмма результатов эксперимента шести моделей БЯМ Наивысший суммарный результат показала модель Grok (163 балла), что позволяет характеризовать её как наиболее устойчивую к разнообразию задач в рамках предложенного набора. Вторую позицию заняла модель DeepSeek с результатом 157 баллов, что также свидетельствует о её высоком уровне производительности. Обе модели показали стабильные результаты, не демонстрируя значительных провалов в отдельных дисциплинах. ChatGPT и Le Chat продемонстрировали сбалансированные результаты, в то время как отечественные модели (GigaChat и YandexGPT) показали конкурентоспособные результаты, сопоставимые с зарубежными аналогами, не демонстрируя принципиального отставания в решении задач школьного и вузовского уровня. Разброс итоговых баллов между моделями, за исключением Grok и DeepSeek, оказался сравнительно небольшим, что свидетельствует о постепенном выравнивании качества генерации ответов среди современных БЯМ. Анализ результатов по учебным дисциплинам показал (Рисунок 2), что ни одна из моделей не достигла максимального балла (30) ни в одной из дисциплин. Наиболее заметно низкие результаты показала модель GigaChat по дисциплине «Интегралы и дифференциальные уравнения», набрав всего 17 баллов и значительно отстав от других моделей (средний балл по дисциплине — 23).
Рис. 2. Диаграмма распределения результатов эксперимента шести моделей БЯМ по учебным дисциплинам В то же время, по остальным дисциплинам GigaChat показал результаты, сопоставимые с конкурентами, что позволяет предположить наличие специфических пробелов в обработке задач по высшей математике. Средний балл по химии (27,5) оказался наивысшим среди всех дисциплин. Проведенный эксперимент выявил как сильные стороны, так и ограничения современных БЯМ в решении образовательных задач. Высокая доля верных ответов с первой попытки (73,9%), низкий уровень галлюцинаций (менее 1%) и конкурентоспособность отечественных моделей подтверждают их значительный потенциал для применения в образовательной практике. Ограниченная способность к самокоррекции и специфические слабости по отдельным дисциплинам указывают направления дальнейших исследований и доработки.
Рекомендовано к публикации: Literature
| |||||||||
|
| |||||||||
| Copyright (C) 2025, Письма
в Эмиссия.Оффлайн (The Emissia.Offline Letters): электронный научный журнал ISSN 1997-8588 (online). ISSN 2500-2244 (CD-R) Свидетельство о регистрации СМИ Эл № ФС77-33379 (000863) от 02.10.2008 от Федеральной службы по надзору в сфере связи и массовых коммуникаций При перепечатке и цитировании просим ссылаться на " Письма в Эмиссия.Оффлайн ". Эл.почта: emissia@mail.ru Internet: http://www.emissia.org/ Тел.: +7-812-9817711, +7-904-3301873 Адрес редакции: 191186, Санкт-Петербург, наб. р. Мойки, 48, РГПУ им. А.И.Герцена Учредитель: Федеральное государственное бюджетное образовательное учреждение высшего образования "Российский государственный педагогический университет им. А.И.Герцена"" Издатель: Консультационное бюро доктора Ахаяна [ИП Ахаян А.А.], гос. рег. 306784721900012 от 07,08,2006.
|